Earlier this week, I got an e-mail from Lucia Santamaria from the "Gender Gap in Science" project from the International Council for Science. They are trying to systematically measure the gender gap in a number of ways, including looking at publication records. One of the important parts of their effort is to find ways to validate methods of gender assignment or inference.
Lucia was writing about some data found in the paper I wrote with with Melanie Stefan about women in computational biology. In particular, she wanted the dataset that we got from Filardo et. al. that had a list of ~3000 journal articles with known first-author genders. This is a great dataset to have, since the authors of that paper did all the hard work of actually going one-by-one through papers and finding the author genders by hand (often searching institutional websites and social media profiles for pictures etc).
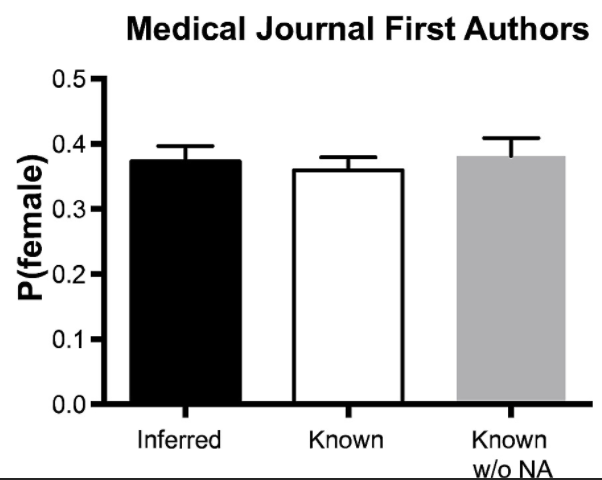
This allowed us to validate our gender inference based on author first name against a dataset where the truth is known (it did pretty well).
And that's what Lucia wants to do as well. There's just one problem: the form of the data from Filardo and colleagues is human-readable, but not machine- readable[1] . For example, one row of the data looks like this:
Article_ID |
Full_Title |
Link_to_Article |
Journal |
Year |
Month |
First Author Gender |
|---|---|---|---|---|---|---|
| Aaby et al. (2010) | Non-specific effects of standard measles vaccine at 4.5 and 9 months of age on childhood mortality: randomised controlled trial | NA | BMJ | 2010 | 12 - Dec | Male |
What we'd really like to have is some unique identifier (eg the Pubmed ID or doi) associated with each record. That would make it much easier to cross- reference with other datasets, including the table of hundreds of thousands of publications that we downloaded as part of this study. I had this when we published - it's how we validated our method, but I'm embarrassed to say it didn't get included with the paper, and I recently had to delete my old computer backups which is the only place it lived.
I told her how we initially did this, and it sounds like she managed to make it work herself, but I thought it would be worth documenting how I did it originally (and maybe improve it slightly). So we've got a table with titles, author last names, years, and journals, and what we want is a pubmed id or doi.
I'm using julia as my go-to language these days, and the first step is to load in the table as a dataframe that we can manipulate:
using DataFrames
using CSV
df = CSV.read("data/known-gender.csv")
# get an array with the "article id" as a string
ids = Vector{String}(df[:Article_ID])
@show ids[1]ids[1] = "Aaby et al. (2010)"We can see that the current form of the :Article_ID has both author name and
the year, but we want to be able to handle these separately. But they all take
the same form, the author name, sometimes followed by "et al.", followed by the
year in parentheses[2]
. So I'm going to use regular expressions, which
can look like gobbledegook if you're not familiar with it. It's beyond the scope
of this post to describe it, but I highly recomend regexr as a resource for
learning and testing. The regex I used for this is composed of 3 parts:
- The author name, which can have some number of letters, spaces,
-, and':([\w\s\-']+)- these are also at the beginning of the line, so I add a
^(just to be safe)
- these are also at the beginning of the line, so I add a
- Then "et al.":
et al\.- the
.is a special character, so it's escaped with\ - this is also optional, so I wrap it in parentheses and add
?
- the
- The year, which is 4 digits, and wrapped in parentheses:
\((\d{4})\)- the inner parentheses are so I can grab it as a group
- it should be the end, so I finish with
$
So, the complete regex : ^([\w\s\-']+)( et al\.)? \((\d{4})\)$
And now I want to apply that search to everything in the Article_ID column:
# confirm this matches every row
length(ids) # --> 3204
sum(.!ismatch.(r"^([\w\s\-']+)( et al\.)? \((\d{4})\)$", ids)) # --> 3204
# apply match across the whole ids array with `match.()`
matches = match.(r"^([\w\s\-']+)( et al\.)? \((\d{4})\)$", ids)
# get the last name of first authors
firstauthors = [m.captures[1] for m in matches]
# get the year... yeah there's a column for this, but since we have it...
years = [parse(Int, m.captures[3]) for m in matches]3204-element Array{Int64,1}:
2010
2007
⋮
2007
2011We also have a column for the journal names, but pubmed searching is a bit idiosyncratic and works better if you use the right abreviations. So next, I built a dictionary of abbreviations, and used an array comprehension to get a new array with the journal names:
journals = Vector{String}(df[:Journal])
replacements = Dict(
"Archives of Internal Medicine" => "Arch Intern Med",
"Annals of Internal Medicine" => "Ann Intern Med",
"The Lancet" => "Lancet",
"NEJM" => "N Engl J Med"
)
journals = [in(x, keys(replacements)) ? replacements[x] : x for x in journals]3204-element Array{String,1}:
"BMJ"
"Ann Intern Med"
⋮
"Lancet"
"Ann Intern Med"Finally, words like "and", "in", "over" don't help a lot when searching, and the
titles currently have special characters (like : or ()) that also don't help
or could even hurt our ability to search. So I took the title column, and built
new strings using only words that are 5 characters or more. I did this all in
one go, but to explain, the matchall() function finds all of the 5 or more
letter words (that's \w{5,} in regex) and returns an array of matches. Then
the join() function puts them together in a single string (separated by a
space since I passed ' ' as an argument):
titles = join.(matchall.(r"\w{5,}", Vector{String}(df[:Full_Title])), ' ')3204-element Array{String,1}:
"specific effects standard measles vaccine months childhood mortality randomised controlled trial"
"Tiotropium Combination Placebo Salmeterol Fluticasone Salmeterol Treatment Chronic Obstructive Pulmonary Disease Randomized Trial"
⋮
"Artemether lumefantrine versus amodiaquine sulfadoxine pyrimethamine uncomplicated falciparum malaria Burkina randomised inferiority trial"
"Patient Interest Sharing Personal Health Record Information Based Survey"So now we've got all the elements of our search, and I just put them into an array of tuples to make them easier to deal with:
searches = collect(zip(titles, firstauthors, journals, years))3204-element Array{Tuple{String,SubString{String},String,Int64,Int64},1}:
("specific effects standard measles vaccine months childhood mortality randomised controlled trial", "Aaby", "BMJ", 12, 2010)
("Tiotropium Combination Placebo Salmeterol Fluticasone Salmeterol Treatment Chronic Obstructive Pulmonary Disease Randomized Trial", "Aaron", "Ann Intern Med", 4, 2007)
⋮Finally, I iterated through this array and composed searches, using the
BioServices.EUtils package to do the search and retrieval.
using BioServices.EUtils
for s in searches
# If you do too many queries in a row, esearch raises an exception.
# The solution is to pause (here for 10 sections) and then try again.
try
res = esearch(db="pubmed", term="($(s[1]) [title]) AND ($(s[2]) [author]) AND ($(s[3]) [ journal]) AND ($(s[4]) [pdat])")
catch
sleep(10)
res = esearch(db="pubmed", term="($(s[1]) [title]) AND ($(s[2]) [author]) AND ($(s[3]) [ journal]) AND ($(s[4]) [pdat])")
end
doc = parsexml(res.data)
#= this returns an array of pmids, since in the xml, they're separated by
newlines. The `strip` function removes leading and trailing newlines, but
not ones in between ids. =#
i = split(content(findfirst(doc, "//IdList")) |> strip, '\n')
if length(i) == 1
#= if no ids are returned, there's an array with just an empty string,
in which case I add 0 to the array =#
length(i[1]) == 0 ? push!(pmids, 0) : push!(pmids, parse(Int, i[1]))
else
# if there are more than 1 pmids returned, I just add 9 to the array
push!(pmids, 9)
end
endI actually did better than the last time I tried this - 2447 records associated with only 1 pmid. 13 of the searches had more than 1 pmid, and the rest (744) didn't return any hits.
@show sum(pmids .> 9)
@show sum(pmids .== 9)
@show sum(pmids .== 0)sum(pmids .> 9) = 2447
sum(pmids .== 9) = 13
sum(pmids .== 0) = 744I added the ids to the dataframe and saved it as a new file (so I don't have to do the searching again). Since I have the urls for many of the papers, I was thinking I could try to identify the doi's associated with them from their webpages, but that will have to wait until another time.
For now, the last step is to save it as a csv and send it off to Lucia:
CSV.write("data/withpmids.csv", df)- ⤶ The input datasets used in this post are available through the Open Science Framework: https://osf.io/hs6ut/
-
⤶
I should note that in the version Filardo et. al. originally sent me, this was waaaay more heterogeneous. Some things had
et. all.oret al, the years weren't always in parentheses etc. I did a lot of manual curration before it got to this point.